
In this blog post, we take a deep dive into using OpenRefine and other tools to convert your tabular metadata into a standards-compliant XML Dublin Core format.
In the third in our series of blog posts discussing how to capture metadata using the DRI Batch Metadata Template, we take a deep dive into using OpenRefine and other tools to convert your tabular metadata into a standards-compliant XML Dublin Core format that can be imported into DRI’s Repository, or other platforms that support Dublin Core. If you’re new to OpenRefine, this one might be a bit advanced, but you can get an excellent introduction to using OpenRefine from this recent Webinar from the Europeana Common Culture project. If you want to learn more about using the DRI metadata template itself, see Parts One and Two in this series.
We recently read an interesting blog post by Kelli Bogan from the National Baseball Hall of Fame Photo Archives, describing the process that they use to extract metadata from digital image files and transform that into MODS XML files. The latter part of the post, which describes how the metadata is exported from OpenRefine and then split into individual XML files, closely mirrors the process that we at DRI recommend to members who have their metadata in spreadsheet formats. In the previous post in this series, we looked at a case study of how an organisation that is gathering data can use pre-existing templates to help them to create rich and interoperable descriptive metadata – again in spreadsheet format. This seemed an opportune time, therefore, to describe in more detail the process that we use to transform this tabular metadata from spreadsheets into XML files that are suitable for ingest into the Digital Repository of Ireland or other digital repositories.
If you are in a similar situation to the Baseball Hall of Fame, with large volumes of uncatalogued images, then we strongly recommend that you have a read through Kelli’s blog post for ideas as to how you can automate the process of extracting metadata from the files themselves. We’re going to assume, however, that you have already done this or that you have manually catalogued your collection and that this metadata is stored in a spreadsheet.
Although you can clean up your metadata within your regular spreadsheet application, just like the Baseball Hall of Fame, we here at DRI recommend the use of OpenRefine. It allows you to transform your metadata in ways that would be much more difficult in an application such as Microsoft Excel. Have multiple subject terms lumped together that you need to split out into individual columns? Need to change the format of author names from Firstname Surname to Surname, Firstname? Want to change your date format from US to UK? All of these tasks, and more, can be done quickly and easily with OpenRefine. There are some good online resources available on how to clean your data using OpenRefine. For example, take a look at the Programming Historian’s Cleaning Data with OpenRefine tutorial and the Europeana Common Culture’s aforementioned webinar: Increasing (raw) data quality using OpenRefine. So, we’ll skip any detailed explanation of how to clean your metadata and start from the point where you are ready to export.
OpenRefine has a sophisticated export templating tool, which allows you to specify exactly how you want your exported metadata to look. You can set an overall prefix and suffix for your exported file (e.g <modscollection> and </modscollection> tags if you are producing MODS XML). You can also specify a row separator.
The part that we are most interested in, though, is the row template. This is because each row in our spreadsheet describes a single digital object. Therefore, each row needs to be transformed into an individual XML document. It is in the row template that we will specify the opening and closing XML tags for each element (cell) within our row.
At the DRI, we support several different metadata standards: (Qualified) Dublin Core, MODS, MARC and EAD. As a general rule though, we recommend Dublin Core for anyone who doesn’t already have a cataloging system in place that uses one of these formats. Dublin Core is flexible and easy to use and understand, but still powerful enough to describe most types of digital object. Therefore, we have produced a sample OpenRefine export template for Dublin Core, and a tool for splitting the exported file into individual XML files.
Our basic export row template looks something like the below. It may look off-putting, but let’s break it down! Focus on the parts in bold. These should be the same as the column headers in your spreadsheet. Note that these are case sensitive, so you should make sure that they match exactly what you have put into your spreadsheet header row:
{{forNonBlank(cells[“Filename“], v, “FILENAME “+v.value, “”)}}
<qualifieddc xmlns:dc=”http://purl.org/dc/elements/1.1/” xmlns:dcterms=”http://purl.org/dc/terms/” xmlns:marcrel=”http://www.loc.gov/marc.relators/” xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=”http://www.loc.gov/marc.relators/ http://imlsdcc2.grainger.illinois.edu/registry/marcrel.xsd” xsi:noNamespaceSchemaLocation=”http://dublincore.org/schemas/xmls/qdc/2008/02/11/qualifieddc.xsd”>
{{forNonBlank(cells[“dc:Identifier“], v, “<dc:identifier>”+v.value+”</dc:identifier>”, “”)}}
{{forNonBlank(cells[“dc:Title“], v, “<dc:title>”+v.value+”</dc:title>”, “”)}}
{{forNonBlank(cells[“dc:Creator“], v, “<dc:creator>”+v.value+”</dc:creator>”, “”)}}
{{forNonBlank(cells[“dc:Date“], v, “<dc:date>”+v.value+”</dc:date>”, “”)}}
{{forNonBlank(cells[“dc:Description“], v, “<dc:description>”+v.value+”</dc:description>”, “”)}}
{{forNonBlank(cells[“dc:Rights“], v, “<dc:rights>”+v.value+”</dc:rights>”, “”)}}
{{forNonBlank(cells[“dc:Type“], v, “<dc:type>”+v.value+”</dc:type>”, “”)}}
{{forNonBlank(cells[“dc:Language“], v, “<dc:language>”+v.value+”</dc:language>”, “”)}}
{{forNonBlank(cells[“dc:Contributor“], v, “<dc:contributor>”+v.value+”</dc:contributor>”, “”)}}
{{forNonBlank(cells[“dc:Source“], v, “<dc:source>”+v.value+”</dc:source>”, “”)}}
{{forNonBlank(cells[“dc:Coverage“], v, “<dc:coverage>”+v.value+”</dc:coverage>”, “”)}}
{{forNonBlank(cells[“dcterms:Spatial“], v, “<dcterms:spatial>”+v.value+”</dcterms:spatial>”, “”)}}
{{forNonBlank(cells[“dcterms:Temporal“], v, “<dcterms:temporal>”+v.value+”</dcterms:temporal>”, “”)}}
{{forNonBlank(cells[“dc:Subject“], v, “<dc:subject>”+v.value+”</dc:subject>”, “”)}}
{{forNonBlank(cells[“dc:Subject2“], v, “<dc:subject>”+v.value+”</dc:subject>”, “”)}}
{{forNonBlank(cells[“dc:Subject3“], v, “<dc:subject>”+v.value+”</dc:subject>”, “”)}}
{{forNonBlank(cells[“dc:Subject4“], v, “<dc:subject>”+v.value+”</dc:subject>”, “”)}}
{{forNonBlank(cells[“dc:Relation“], v, “<dc:relation>”+v.value+”</dc:relation>”, “”)}}
</qualifieddc>
So, the example above could be used with a spreadsheet that looks something like this:
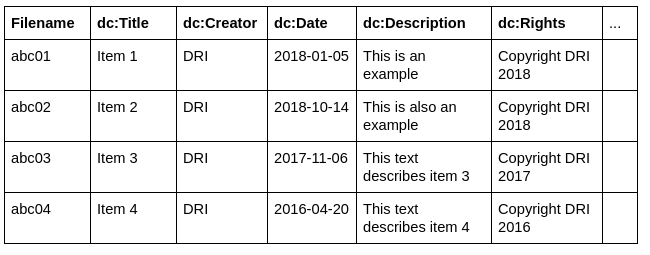
Each column header in the spreadsheet appears in the export template, and the rest of the template line is telling the export engine how to format the value of that column within the output file, e.g.
{{forNonBlank(cells[“Rights“], v, “<dc:rights>”+v.value+”</dc:rights>”, “”)}}
Tells OpenRefine that the value of each cell in the Rights column needs to be formatted to appear on its own line, with the string <dc:rights> before it and the string </dc:rights> after it, i.e.:
<dc:rights>Copyright DRI 2017</dc:rights>
The parts inside the pointy brackets are all part of the Dublin Core XML specification. The line:
<qualifieddc xmlns:dc=”http://purl.org/dc/elements/1.1/” xmlns:dcterms=”http://purl.org/dc/terms/” xmlns:marcrel=”http://www.loc.gov/marc.relators/” xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=”http://www.loc.gov/marc.relators/ http://imlsdcc2.grainger.illinois.edu/registry/marcrel.xsd” xsi:noNamespaceSchemaLocation=”http://dublincore.org/schemas/xmls/qdc/2008/02/11/qualifieddc.xsd”>
Specifies the XML header line, which is also required in order to make your Dublin Core XML file valid, as is the footer line </qualifieddc>. There is one other line in our template that you need to be aware of:
{{forNonBlank(cells[“Filename“], v, “FILENAME “+v.value, “”)}}
This tells the template to put the value of the Filename column on a line on its own before the XML record for each row. The exported record will look like this:
FILENAME abc01
<qualifieddc xmlns:dc=”http://purl.org/dc/elements/1.1/” xmlns:dcterms=”http://purl.org/dc/terms/” xmlns:marcrel=”http://www.loc.gov/marc.relators/” xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=”http://www.loc.gov/marc.relators/ http://imlsdcc2.grainger.illinois.edu/registry/marcrel.xsd” xsi:noNamespaceSchemaLocation=”http://dublincore.org/schemas/xmls/qdc/2008/02/11/qualifieddc.xsd”>
<dc:title>Item 1</dc:title>
<dc:creator>DRI</dc:creator>
<dc:date>2018-01-05</dc:date>
<dc:description>This is an example</dc:description>
<dc:rights>Copyright DRI 2018</dc:rights>
…
</qualifieddc>
And the exported file will be made up of multiple records such as this – one for each row in your spreadsheet. It is important to note that this is not an XML file – it’s just a text file containing multiple XML records. The final step, therefore, is to split these up into individual XML files.
The Baseball Hall of Fame use an open source tool called xml_split to do this splitting. This works well for them because they are using MODS, and MODS has an overall modscollection XML tag that allows you to collect multiple MODS records into a single file. In our case, however, we are using Dublin Core – which does not have a corresponding collection element – so our exported file is not actually valid XML yet, and the xml_split tool won’t be able to split it. We, therefore, wrote our own tool to do the splitting for you. It is available here: https://github.com/Digital-Repository-of-Ireland/dri-open-refine-split.git
Download this tool and run the split.py Python script (you may need to install Python 3 and, optionally, the Python 3 Tkinter module). It will search for rows with a FILENAME entry and will use that value to create an xml file (e.g. abc01.xml, abc02.xml, etc.). It will then put the following XML record into that file, from the header line all the way to the closing </qualifieddc> tag, at which point it will close that file and move on to the next one. If you don’t include the FILENAME lines, it will just name the files 1.xml, 2.xml, 3.xml, and so on.
The result of all of this will be a folder of individual XML Dublin Core files, one for each digital object. The DRI’s Batch Ingest interface provides an easy way to ingest these into DRI, or they can be imported into other repositories that support Dublin Core.
We hope that you have found this short series of blog posts helpful. If this has left you with any remaining questions or comments, regarding these posts or the DRI Batch Metadata Template, you can get in touch with the DRI team at dri@ria.ie.
[Photo by Sergey Zolkin on Unsplash]